The AI Stack Is Specializing, with Silicon Leading the Way

By Lance Matthews, Yan Bieger & Jonli Keshavarz
On Christmas Eve, Groq and NVIDIA announced a massive milestone for the AI inference stack a $20 billion non-exclusive technology licensing agreement. Shortly after, Groq leadership transitioned over to NVIDIA, and NVIDIA and Groq will be working together to fulfill the inference needs of developers. Despite only recently announcing our participation in the company’s $750m Series D a few months earlier, we at DTCP are very excited for the company, the investors, and the Groq leadership team and everyone at the company who has been building since 2016.
The "Efficiency Tax" of the Generalist
In historical technology cycles, the transition from general-purpose to purpose-built tools is a reliable indicator that a market is moving from experimental "early days" to industrial-scale utility. In the 19th century, during the railroad era, this meant shifting from wooden boxcars - which shipped everything from coal to cattle - to specialized fleets like refrigerator cars. In 2026, we are seeing the same logic play out in silicon, now driven by inference rather than transport.
Andrew Carnegie was the most ruthless “specializer” in industrial history, he understood that general-purpose systems create an efficiency tax that compounds quickly and becomes an existential liability. He would routinely scrap general-purpose machinery that still worked just to install a new, purpose-built machine that was 5% more efficient.

"An iron railroad would be a cheaper thing than a road of the common construction." > — Andrew Carnegie
This is exactly why the NVIDIA-Groq agreement is so significant. By securing a non-exclusive license to Groq’s software-defined, deterministic architecture, NVIDIA is acknowledging a fundamental shift:
- The GPU is for Training: Its flexibility is perfect for the varied and unpredictable demands of building models.
- The LPU is for specialized Inference execution: Its purpose-built design is required for the low-latency execution that defines the "Inference-as-a-Service" era.
But, why now?
Expanding workflows and compounding latency
Early on, we viewed inference as a latency story: take a one-shot response from “fast” to “faster.” Useful, but often this was incremental. The bigger unlock is what happens when AI shifts from chat to work: multi-step, tool-using reasoning agents where end-to-end time compounds across dozens of LLM calls using inference-time compute. Compressing a 20-step workflow to be 10x faster expands the set of tasks that are economically and operationally viable.
Back in 2024, a year prior to our investment in Groq, we began digging into this problem. Below is an excerpt from one of our early internal thesis documents on the Inference-as-a-Service space.
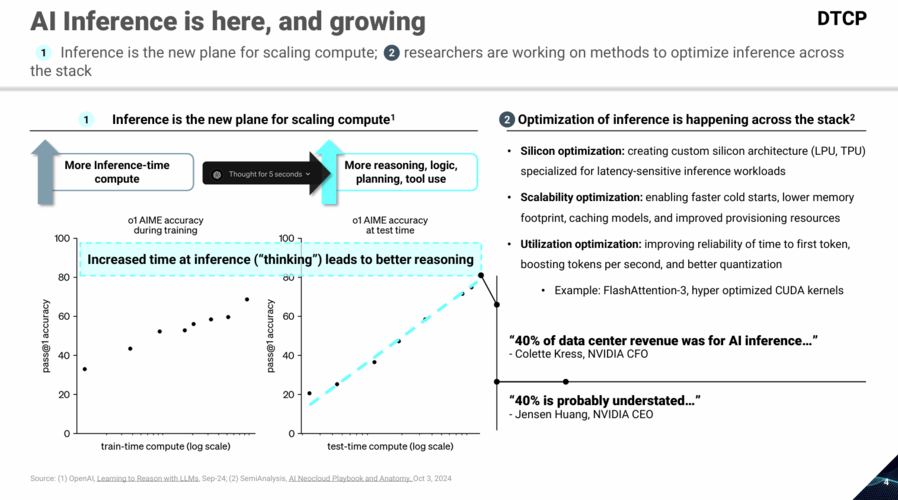
This is the inflection point at which architecture matters more than optimization. Once inference becomes a chained workflow rather than a single response, variance, jitter, and tail latency start being bottlenecks. General-purpose systems can be tuned, but they cannot escape these structural limits. Purpose-built inference systems, by contrast, are designed from first principles to deliver predictable performance at scale.
Specialization Cascades Across the AI Stack
This moment in AI mirrors a familiar pattern from prior industrial revolutions. Railroads moved from general-purpose boxcars to specialized fleets; electricity shifted from localized generators to optimized grids; manufacturing evolved from flexible workshops to tightly tuned assembly lines. In each case, early generality accelerated experimentation but once systems reached industrial scale, specialization became unavoidable. The efficiency tax of general-purpose design compounded until purpose-built systems were the only viable path forward.
Looking ahead, inference will not be the only layer of the AI stack forced to specialize. As AI systems mature into production-grade, multi-step workflows, similar pressures will emerge across adjacent layers from runtime and memory hierarchies to orchestration, serving, and system-level software. Wherever general-purpose abstractions introduce variance, jitter, or hidden coordination costs, they will become bottlenecks at scale. As with inference, these constraints are structural, not optimizable away, and will increasingly be addressed by purpose-built designs rather than incremental tuning.
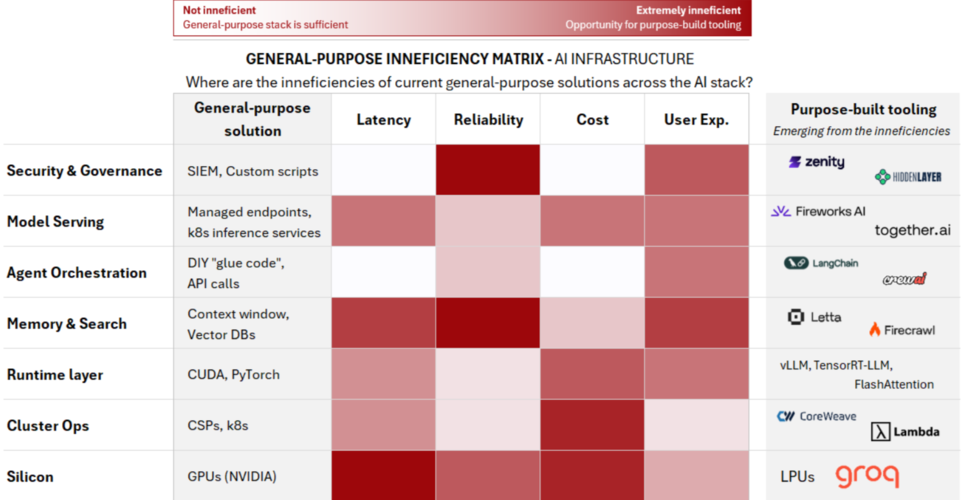
Summary
At DTCP, our investment in Groq was based on a three-point thesis:
- the inevitability and importance of specialization at this point in the AI cycle - specifically around inference;
- the differentiated LPU architecture combined with a best-in-class go-to-market strategy as a Token-as-a-Service platform; and
- the team - led by Jonathan and joined by an exceptional group - is perhaps the only thing more unique than the chip design itself.
The NVIDIA–Groq partnership is a clear signal that inference has reached the stage where focus beats flexibility. Purpose-built systems are no longer optional - they are becoming the foundation of AI at industrial scale.
Looking ahead, we continue to be excited by builders designing specialized AI infrastructure - across silicon, systems, and software - that trades generality for performance, predictability, and scale. We welcome conversations with teams taking a similarly focused approach to the next phase of the AI stack.